 Owen
Owen给Zola博客增加搜索功能
我觉得个人博客的一个最大的好处就是我可以把它当成任何东西的试验田,弄坏也没事,反正这只是我的个人数字花园而已。所以昨天我给博客新加了一个搜索页面,以及首页也添加了一个搜索框。
我一直在这个博客里存放自己的所有公开内容,包括笔记和文章,我经常需要搜索自己的笔记,在此之前,我一直用 VSCode 在本地搜索文档。但是 VSCode 其实启动挺慢的,而且如果不在电脑边,也没法用,所以最近就研究了几种搜索方案。最终我选择了自托管 Rust 开发的Meilisearch,但是这也不是特别理想的方案,因为需要在自己的 VPS 服务器上托管,对于静态博客来说,多了一环需要动态运行的服务需要维护。但是这已经是目前最不差的方案了。
对于静态博客的搜索,我了解的主要有 4 种主流方案,一是客户端搜索,另一种是很流行的使用Algolia的搜索托管服务,还有一种是使用搜索引擎比如谷歌的索引结果,最后就是我最终使用的 Algolia 的开源替代方案 Meilisearch这类的自托管。
客户端搜索
客户端搜索是最符合静态博客定义的,完全不依赖服务端,zola 博客内置的搜索功能也是这样,其原理是 build 的过程中,生成整个网站的搜索的 JSON 索引文件,在前端网页提出搜索请求后,用 js 去搜索这个索引,然后找出对应的结果。这个索引可大可小,如果你只索引标题和路径的话,那么索引就很小,但是如果你索引全文的话,取决于你的文档大小,索引可能会很大。Zola 目前内置的搜索使用 elasticlunr, 其实已经 3 年没有更新了,项目处于等继承者状态。另一个就是,这个基本上是不支持中文搜索的,虽然 Zola 有选项可以建立中文的搜索索引,但是前端库方面对于中文的支持处于不可用的状态,我试过接入,但是太多 bug 了,之前看到一个日本博主好像确实有成功集成日文搜索, 我仿照的时候也失败了。
为什么对于中文搜索需要专门支持呢?因为所有类似的全文搜索实现都是要先建立一个倒排索引(听起来很牛逼,其实就是词语对文章 id 的哈希索引),类似下面这样:
{
"Hello": ["/hello", "/world"],
"World": ["/world", "/foo"]
}有了这个索引,就能很快的找到最相关的文章。这种索引对于类似英语的语言来说很好实现,因为英语中分词很简单,只需要根据空格就能把所有词语分开,但是中文没有用空格分开的习惯,所以需要很大的词语字典,然后从字典里找到相关的词语,然后再建立分词索引。这才完成第一步(这个比较好解决,因为这一步发生在编译阶段,有足够的资源去做这件事)。第二步是从客户端发出搜索请求,这一步依然需要分词,比如用户搜索如何给zola博客添加索引,搜索引擎首先要把这句话分为如何,给,Zola,博客,添加,索引,然后再去对应的索引里进行最佳匹配查询。所以我觉得对于中文搜索,在客户端做是不现实的,因为基本上没法在客户端上进行复杂的分词,而且随着文档的增加,全文搜索的索引还会进一步增加,全部加载到客户端看起来也不是一个很道德的选择。
WASM 怎么样?
WebAssembly 以作为 js 的高性能支持方案进入了主流浏览器的支持,你可以用 Rust, C++,或者任何你喜欢的语言来编写高性能的 WebAssembly 应用,然后在前端调用。
对于 WASM,看到过几个有意思的项目,比如sql.js-httpvfs, 把 sqlite 数据文件存储到 CDN 服务器上,然后前端用含有内嵌 sqlite 的 wasm 去读取数据,充分利用了 sqlite 的高效,从而实现让 web 客户端完全摆脱服务端数据库的依赖。
我也找到了几个关于 WASM 搜索的项目,主要包括:tinysearch ,stork, edgesearch
Tinysearch
用 Rust 编写,原理和 js 客户端搜索基本类似,只不过把索引打包到 wasm 里面,最终的 wasm 大小可以是 100k 以内,但是也只支持英文。我把源码下载下来,然后把分词逻辑换用Meilisearch 的分词,尝试打包我目前的博客,发现总共也才 113K,这 113K 是同时包括搜索逻辑和索引数据的哦,而用 Zola 自带的搜索打包的纯中文索引数据是 3.5M,英文索引是 650K, 可见 tinysearch 的作者真的做了很多优化,作者也写了一篇详细的文章记录优化的过程。但其实这样对比是有一点不公平的,因为Zola 的索引会有更好的搜索体验,你可以在文档网站体验一下, 而Tinysearch则为了性能做了一些取舍,比如不支持前缀搜索,搜索结果只显示标题,没有上下文,也没有高亮等等,但是从性能角度,我觉得这种方案算是客户端搜索的天花板了。
Stork
同样也是 Rust 编写,只支持英文,颜值很好,接入体验也很棒,搜索结果还能高亮,也有上下文,基本上和Algolia类似,也使用了 wasm,不过 Stork 是把搜索逻辑单独打包成一个 wasm,然后把索引数据另外打包成另一个st文件,然后搜索的时候动态的加载索引数据。这样的操作其实多了一步序列化和反序列化的步骤。我也尝试把其内置的简单英文分词逻辑换用Meilisearch 的分词,但是发现我的索引数据竟然达到了 85M(可能有别的坑,因为我只是简单的替换了分词的函数),所以就没有更多的体验了。这也印证了,想在客户端把搜索体验做好,确实需要权衡你的索引大小。
edgesearch
我喜欢这个哥们的概念,无服务器 Serverless 搜索,通过把 WASM 部署到 Cloudflare Workers 上,然后客户端通过网络请求进行搜索,我觉得这是最有戏的方案,我喜欢 Cloudflare Workers 这种一次书写,永远忘记的无服务器系统,而且每天还有 10 万请求的免费额度,同时作为基于 Chrome V8 中有限制的无服务器,冷启动又贼快,所以我觉得静态博客的最佳搜索方案就是这样了。虽然有一点点动态,但是我们用了最具有扩展性的方案,我倾向于认为这是必要的权衡。说回 EdgeSearch,它也是先 build 索引,然后把索引上传到 cloudflare 的 KV 内存数据库里,然后通过 wasm load 索引,进行搜索,性能很高,只是它目前只是处于实验阶段,接入需要自定义很多东西,而且也不支持中文,我个人很希望这个项目能获得更多的牵引力。
难道只能用云搜索服务了吗?
Algolia
即刻搜索的鼻祖和天花板,我在Actionsflow 的文档网站中用了他提供给开源项目的免费服务,接入和界面都是一流的,不信你去看tailwindcss的搜索体验,太棒了。唯一的问题就是贵,如果不差钱,那我觉得这是最佳选择了。他家同时也是Hacker News的御用搜索,我经常用来搜很多东西, 感谢感谢!
Sourcegraph
我在阮老师的科技周刊里看到阮老师给用户的其中一个搜索选项是利用 https://sourcegraph.com/github.com/theowenyoung/blog 提供的对 Github 源码的免费搜索服务,我试了一下,搜索准确度非常高,但是只能链接到源文件,没法回到对应的网页,但是由于博客内容是用 markdown 写的,所以纯文本也没问题。所以,这是一个不错的替代品。我在Search也添加了一个表单搜索链接过去,你可以体验一下。
VSCode Web 版(Github1s)
你只需要在 github 的网址上加上1s之后,就能用浏览器以 VSCode 的方式打开你的 github repo,比如我的博客对应的地址就是:https://github1s.com/theowenyoung/blog ,这里自带 VSCode 的全局搜索,所以就可以直接在浏览器上搜索博客内容,这其实也是一个很好的搜索替代方案,完全不用担心自己托管,搜索速度也超快,就是差一个直接指向搜索并且带搜索参数的链接,我提了一个Issue,结果他们回复其实他们用的是我上面提到的 Sourcegraph 的搜索,被骗了!我以为是 VSCode 自带的搜索!但是还是期待一下后续的进度,希望能有一个直链,支持类似这样的链接https://github1s.com/theowenyoung/blog/panel/search?q=term&files-include=content,这样就可以直接从我的博客里的搜索框跳转到 vscode 的全局搜索里,体验更好。不过这个工具的问题也是首次启动挺慢的,期待微软官方能出一个类似的工具,因为反正 github 也是他家的,可能会更快。
Google 网站搜索
你可以在谷歌的搜索框里加上site:www.owenyoung.com来指定搜索对应的网站,速度极快,缺点是可能收录不全。Anyway, 我在Search也添加了一个表单搜索链接了过去,你可以体验一下。
自托管方案
Meilisearch
美丽搜索?是一个用 Rust 写的美丽的 Algolia 的开源替代,我喜欢这个名字哈哈哈,美丽!Evething is ok, 就是界面相比 Algolia 还是差了那么一点点。使用流程是:在服务端启动服务后,每次你的静态博客编译后,请求 meili 的接口,把要索引的文档通通丢给他,然后他就会立刻建立索引,客户端就可以搜索里。meili 提供了客户端 js 库让我们可以方便地一键接入。我研究了美丽自己的文档网站 (源码),发现他的接入流程更美丽,用 Github 的Action去扫描整个站点的 sitemap 文件,然后做一些针对网站排版的简单配置,就可以美丽的,有层次的索引你整个网站了。本来以为建立索引挺慢的,但是后面发现 1 分钟左右就能扫描完成,可以在Search 页面体验一下这个搜索结果的层次感!(顺便说一下,这些功能 Algolia 都有哈!),这个层次感是我决定采用它的最重要的原因,因为它是针对文章的各种二级,三级标题,以及内容所在的大标题做的更有细节的索引,所以在搜索结果中,可以直接从结果中点击进入到对应文章的锚点。以下是扫描全站的核心配置:
{
"selectors": {
"lvl0": {
"selector": ".detail-page .p-category",
"default_value": "Random"
},
"lvl1": {
"selector": ".detail-page .p-tags",
"default_value": "Notes"
},
"lvl2": ".detail-page .entry-title",
"lvl3": ".e-content h2",
"lvl4": ".e-content h3",
"text": ".e-content p, .e-content li"
}
}这样的配置的话, meilisearch 建立的索引是细节到具体的小标题和段落上的,可以让搜索体验直接上升一个层次。所有配置见这里
我的部署过程
先在 VPS 上搭建 Meili,见我的 meilisearch dotfile 配置,并不复杂,是我最喜欢的单一二进制文件,无依赖。
在 Github Actions 的中添加步骤,在网站更新后,立刻爬取整个网站.见build.yml 以及爬取的配置文件,得益于我上次在Now, I'm in IndieWeb?中给网站的结构添加了很多有用的标记,所以很好定位到我的一级标题,二级标题,分类等, 我在配置中排除了列表页面,让他只爬取文章页。
Over! 其实说的简单,但是我在建立索引的过程中多次调整了页面中 tag 的层级和 class 以便机器人可以更好的定位到需要的内容(面向机器人编程),最终打磨出来的效果就是:
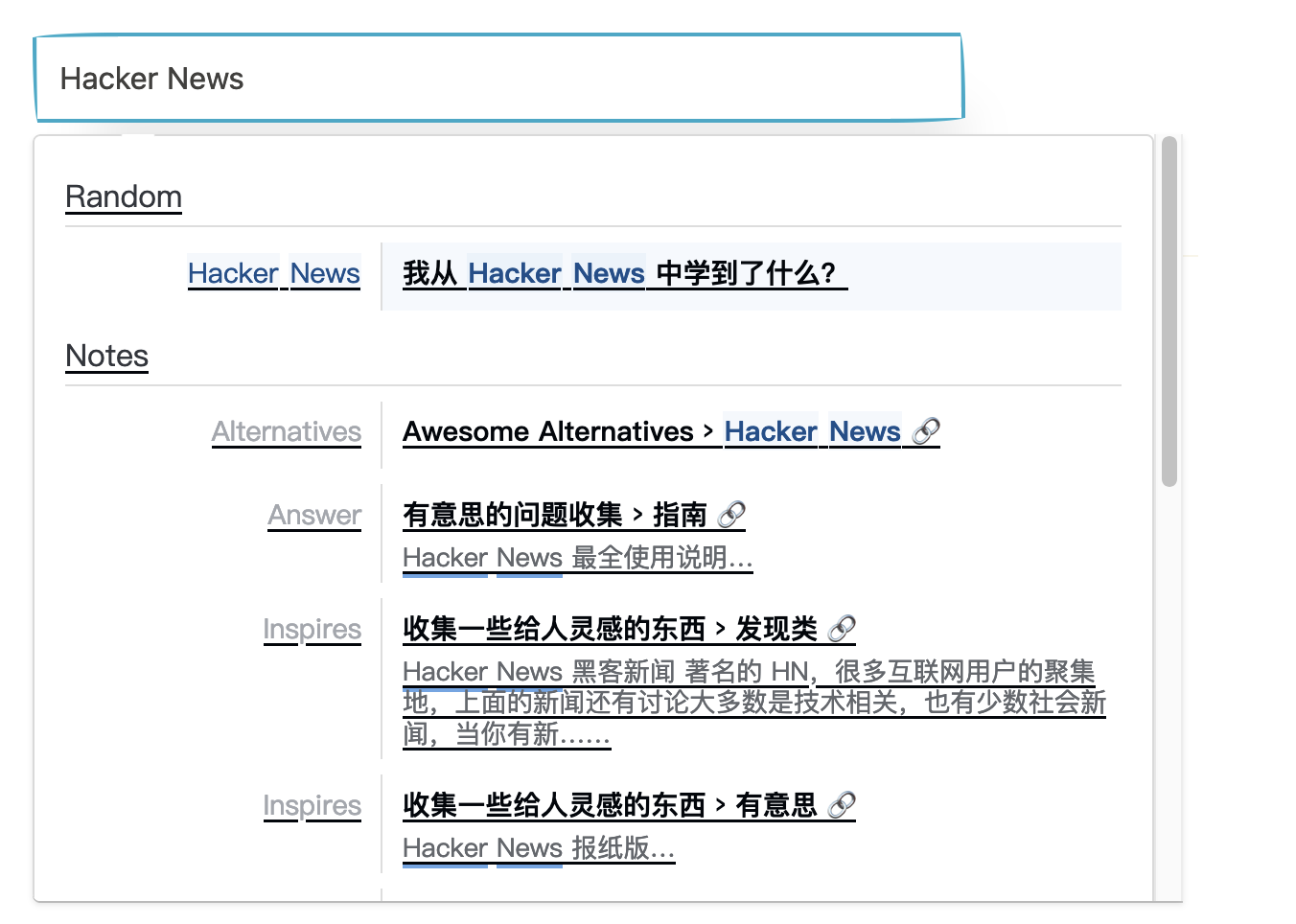
搜索页面的模版文件在这里
升级的时候可能比较麻烦,我通常就是直接删除数据库,反正可以重新构建,跑一下 CI 就可以了。
升级后需要重新获取 admin key:
make meilikey结论
虽然目前用 Meilisearch 解决了搜索的问题(而且体验超好),但是还是更喜欢Edgesearch的方案,这样我就能把搜索部署在类似 Workers 和 Deno Deploy 的平台上了。我不喜欢 Lambda 和 Vercel 的无服务器,虽然限制更少,但是相应的冷启动有点久,不够纯粹。我的理想方案应该是这样,它是一个通用的站内搜索引擎:
通过 Fork 一个 Cloudflare Worker 项目即可部署自己的搜索引擎,带一些很少的配置。
这个搜索引擎会暴露一个开始索引的路由,你会给这个路由提供一个配置文件,然后告诉他
sitemap文件,以及要索引的区块配置。这个搜索引擎暴露几个类似 Algolia 的接口让前端可以搜索,以及管理索引。
基本上就是把我在 meilisearch 上做的事搬到 wasm 上,但是我更喜欢在 cloudflare workers 上部署搜索服务的方案,因为它更简单,更快,更具有扩展性。
我目前是把 Meili 部署在我的一个 4g 内存位于日本的服务器,这台服务器还部署了我很多其他的东西,如果你也想要接入美丽搜索,但是不想自己部署服务端(我懂),可以邮件或者私信我,我告诉你我的 Master Key,然后你也可以利用https://meilisearch.owenyoung.com/建立你的博客索引了。但是这是玩具产品,不能保证可用性,后续也可能被替换,但是终止前我会提前通知你~
更新:我目前把 Meilisearch 从我的 VPS 迁移到免费的Mogenius,更省心,这样就算我弄乱 VPS 的情况下,搜索也不会轻易下线,我也写了一篇文章记录整个过程